Statistikaameti andmekool #15: juturobotid ei sobi ametliku statistika pärimiseks
Kui liidame inimese kalduvusele teisi kergesti usaldada juturobotite enesekindla suhtlusstiili, on usaldus algoritmi vastu kerge tekkima. Vähetuntud faktide ja ametliku statistika pärimiseks tuntud juturobotid ei sobi.
Kuidas kogutakse Eesti elu puudutavaid andmed ja mida nendega tehakse? Kuidas saab rahvaloendusel kõik Eesti inimesed üles lugeda, kui minu ukse taga ei käinud keegi? Kuidas minu elu sellest paremaks muutub, kui SKP-d arvutatakse? Statistikaameti blogisari „Andmekool“ tutvustab ameti tööd ja statistika tegemist lähemalt!
Tänavu läksid Nobeli preemiad nii füüsikas kui keemias arvutiteadlastele, kes on teinud läbimurdeid tehisintellekti valdkonnas. Paari aastaga on generatiivne tehisintellekt vallutanud ajakirjanduse, haridussüsteemi, juristide, poliitikute, investorite ja tippjuhtide meeled. Kõige kuulsam näide generatiivsest tehisintellektist on 2022. aastal ülemaailmselt kättesaadavaks tehtud juturobot ChatGPT.
Generatiivsed mudelid ehk suured keelemudelid on treenimise käigus töötanud läbi massiivses koguses andmeid ja suudavad inimese antud sisendi põhjal genereerida väljundi, mis kohati sobib antud sisendiga väga hästi. Näiteks võid saada ammendava vastuse oma küsimusele või pildi, mis vastab sinu ettekujutusele. Sellised tehisintellektid on mõne aastaga muutnud igapäevaseks jututeemaks töökohtadel ja eraelus ka erialavõõraste inimeste seas. Pole kahtlust, et erinevad tehisintellekti rakendused on mõnes valdkonnas saavutanud hämmastavaid läbimurdeid. Huvi tehisintellekti vastu on suur ja ootused näivad olevat kõrgel.
Millest me räägime, kui räägime tehisintellektist?
Ühtpidi on tehisintellekt arvutiteaduse haru nagu mikrobioloogia on bioloogia haru. Teisalt on tehisintellekt konkreetse, intellekti meenutava andmetöötluse võimekusega masin. Näiteks masin, mis tunneb mammograafiapildilt ära vähkkasvaja või masin, mis oskab sinu varasema meediatarbimise järgi soovitada sisu, mis sulle tõenäoliselt huvi pakub.
Praegune generatiivsete mudelite hullustus võib jätta mulje, et tehisintellekt on midagi palju konkreetsemat kui arvutiteadlased seda ise mõistavad. 2016. aastal avaldatud raamatus „Deep learning“ – mida on käsitletud masinõppe piiblina ja millele Google Scholari andmetel on praeguseks viidatud üle 68 827 korra – on ilmekas Venni diagramm, mis selgitab tehisintellekti ja masinõppe olemust. Diagrammil on masinõpet kujutatud tehisintellekti allosana. Mitte ainult suured keelemudelid, vaid kõik masinõppe süsteemid käivad tehisintellekti kategooriasse.
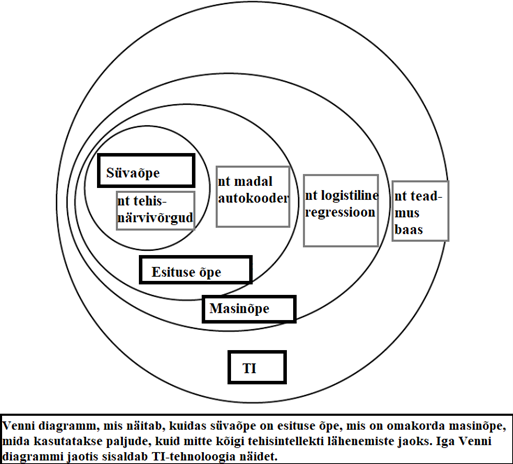
Sel aastal vastu võetud Euroopa Liidu tehisintellekti seadus defineerib tehisintellekti süsteeme üldsõnaliselt ning suured keelemudelid on seal käsitletud kui üks tehisintellekti liik. Algoritmi keerukust ega mudeli suurust definitsioon ei käsitle, seega tegu on samamoodi väga laia kategooriaga. Eriti tähtis on mõiste laiust teadvustada tehisintellektide rahastamisel ja reguleerimisel – lisaks tehisintellekti eesmärgile ja mõjudele tasuks ehk ka arvestada süsteemi keerukust. Kui lihtsa algoritmiga saab saavutada peaaegu sama täpse ja võibolla veidi usaldusväärsema tehisintellekti kui keerulise algoritmiga, ei ole mõtet rahastada keerulisemat ja töömahukamat lahendust. Kui tehisintellektide juriidiline reguleerimine toob arendajatele ja kasutajatele lisakohustusi, on oht ebamõistlikuks koormuseks teadlastele ja analüütikutele, kelle jaoks lihtsamate masinõppemudelite treenimine ja kasutamine on igapäevane töö.
Tehisintellekt statistikas pole midagi uut
Nii eespool viidatud masinõppe piibel kui ka tehisintellekti seadus määratlevad tehisintellekti kategooriasse sadu miljoneid maksvaid suuri ja läbimurdelisi keelemudeleid ja ka lihtsaid ning igapäevasemaid regressioonimudeleid, mida näiteks statistikaamet on väga pikka aega kasutanud. Masinõpe on tüüpiline tööriist auklike andmestike parandamiseks. Näiteks kui statistikaametil pole mõnes andmestikus täielikke andmeid tööga hõivatuse kohta, saab olemasolevate andmete pealt treenida logistilise regressiooni mudeli, mis oskaks puuduvad väärtused mõistlikult asendada (imputeerida). Eriakirjanduses enamasti selliseid mudeleid tehisintellektideks ei nimetata, aga ülaltoodud tehisintellekti definitsioonidele vastavad need küll.
Mida selgemini mudelit mõistame, seda paremini saame hinnata selle usaldusväärsust
Lihtsad regressioonimudelid, mida statistikas kasutatakse puuduvate väärtuste imputeerimiseks ja suured keelemudelid (näiteks ChatGPT kõige „targem“ versioon GPT-4o, mis suudab peale teksti töödelda ka heli ja pilti) asuvad tehisintellekti keerukuse skaala vastandotstes. Võrdleme neid kahte ekstreemumit nüüd küsimuses, kuivõrd võiks kasutaja neid usaldada.
Regressioonimudel hõiveseisundi ennustamiseks võib sisuliselt tähendada algoritmi, kus on vähem kui 10 õpitavat parameetrit ja mille toimimist me suudame üpris selgelt mõista ja kirjeldada. Näiteks saame lihtsasti tõlgendada regressioonikordajaid ja järeldada, et mida väiksem sissetulek ja mida rohkem vaba aega, seda enam kaldub mudel ennustama, et inimene on töötu. Kuna mudelil on kindel fikseeritud sisendi formaat ja me saame kasutada osa neid andmeid, mida me inimeste töötamise kohta teame, testandmestikuna, saame ka üsna lihtsalt mõõta ja mõista selle mudeli toimimist, täpsust ja usaldusväärsust. Mida selgemini me ise masinõppe mudelit mõistame, seda paremini saame hinnata selle usaldusväärsust ja piiranguid.
Suurte keelemudelite puhul räägitakse õpitavate parameetrite arvust aga kümnete ja sadade miljardite suurusjärgus ning inimene ei ole võimeline kogu mudelit hoomama. Näiteks GPT-4o puhul võib sisend varieeruda paarist sõnast kuni mahukate pildi, teksti ja heli kombinatsioonideni. Olenevalt sisendist ja mudeli kasutamise eesmärgist võib väljundi asjakohasuse hindamine osutuda väga keeruliseks. Kohati võib see tähendada põhjalikku infootsingut klassikalistest otsingumootoritest ja nii kaotab keelemudeli kasutamine enda esialgse mõtte.
Miks ei tasu juturobotilt küsida ametlikku statistikat?
Mõnda aega tagasi jõudis statistikaametini ühe riigiameti päring, mis omakorda viitas kodaniku päringule, kus kodanik soovitas riigiametnikul hinnata kindla perioodi metsamaterjali hinda Eestis suure keelemudeli ehk nii-nimetatud juturoboti abiga. Riigiametnik tegigi tehisintellektiga katsetuse ja lõpuks küsis andmeid statistikaametilt. Ehkki kõnealusel juhul pöördus riigiametnik lõpuks ikkagi statistikaameti poole, on märgiline suundumus, et inimeste usaldus juturobotite vastu on sedavõrd suur ja neilt selliseid andmeid küsitakse. Kuivõrd inimeste jaoks on juturobotite aluseks olevad algoritmid aga raskesti hoomavatavad ja nende abiga saadav tulemus keeruliselt kontrollitav, on oht eksitavate andmete levimiseks.
Kui inimene küsib juturobotilt metsamaterjali hinda, peab ta arvestama, et mudeli treeningandmetes ei pruugi olla usaldusväärsed andmed metsamaterjali hindade kohta konkreetsest riigist ja ajaperioodist. Isegi, kui juturobot on selliseid andmeid treenimise käigus näinud, käsitleb mudel neid arvusid numbritena (sümbolitena, mitte suurustena) ning ei pruugi konkreetset tekstijuppi üks-ühele meelde jätta ega õige küsimuse peale korrektselt taasesitada.
Metsamaterjali hindade „pähe õppimine“ ei tundu niivõrd tõenäoline kui muru värvi meelde jätmine
Suured keelemudelid on treenitud ennustama järgmist sümbolit sümbolite jadas ning selle ülesande edukaks täitmiseks paistab olevat kasulik omandada intelligentsust meenutavaid omadusi. On aga tähtis mõista, et keelemudeli treenimisel ei ole väljundi tõepärasust otseselt arvestatud, vaid eeldatakse, et treeningandmetes on piisavalt tõepärast infot kandvat teksti, et järgmise sümboli edukaks ennustamiseks peaks mudel teatud faktiteadmised meelde jääma. Väikeriigi metsamaterjali hindade „pähe õppimine“ ei tundu niivõrd tõenäoline kui muru või taeva värvi meelde jätmine. Vähetuntud faktide ja ametliku statistika pärimiseks sellised juturobotid ei sobi.
Inimene kaldub loomupoolest teisi inimesi üpris kergesti usaldama – see annab meie liigile võime grupiviisiliselt organiseeruda ja koostöös saavutada kõigile grupiliikmetele suuremat väärtust, kui üksi pusides oleks võimalik. Ajastul, kus oleme harjunud teiste inimestega suhtlema tekstiakendes meie ekraanidel, võib ka ChatGPT tekstikast näida meile inimesesarnasena. Kui liidame inimese kalduvusele teisi kergesti usaldada juturobotite enesekindla suhtlusstiili ning arvestame massiliselt leviva tehisintellekti tähtsustamisega kõikides eluvaldkondades, on kerge tekkima liigne usaldus masinõppe mudeli vastu. Nii kaldume algoritmi pidama pädevamaks, kui see tegelikult on.
Tehisintellekti pimesi usaldamise probleem on üleilmne
Laialt levinud vastutustundetut suhtumist juturobotitesse peegeldab uuringu* tulemus, kus üle 1000-st küsitletud organsatsioonist 88% nõustusid väitega, et „kõigi seotud riskide maandamise eest vastutavad alusmudeleid arendavad ettevõtted, mitte neid mudeleid kasutavad organisatsioonid“. Teisisõnu: organisatsioonid üle maailma ei soovi näha vastutust iseendal kui tehisintellekti kasutajatel, vaid näevad vastutust ainiti nende loojatel. Võibolla on selle tulemuse taga instinktiivne vastutuse mujale suunamine ärihuvide kaitseks. Võibolla nähakse ette, et organisatsioonil ei ole võimalik kontrollida kõiki juturoboti kasutamise juhtusid kõigi töötajate poolt. Samas, vaadates teisi tehnoloogiaid – näiteks tulirelvasid või mürgiseid puhastusvahendeid – on selge, et lõpuks lasub ka kasutajal endal.
Tehisintellekt ei ole paari aasta eest tekkinud nähtus, vaid see on ligi 70-aastase ajalooga arvutiteaduse haru, mis tegeleb ka inimesest oluliselt vähemintelligentsete andmetöötlussüsteemidega. Selle teadusharu algoritmid on täitnud intelligentsust meenutavaid praktilisi funktsioone juba pikka aega: tehisintellekt, mis suudab eristada rämpsposti väärtuslikest e-kirjadest säästab meie aega ja närve iga päev juba mitukümmend aastat.
See, et populaarsed juturobotid jätavad intelligentse mulje ning et seda valdkonda on hakatud suurelt rahastama, ei tähenda, et üldine suur keelemudel suudaks kõiki probleeme kõigis eluvaldkondades sama hästi lahendada. Ei maksa ka oodata, et transformer-algoritm, mis on peamine algoritm kaasaegses generatiivses tehisintellektis, on tehisintellekti valdkonna ajaloo lõpp ja toob meile lähiaastatel inimesest intelligentsema, teadvusel oleva ja mõtleva üldise tehisintellekti. Algoritmide väljundisse tuleb suhtuda kriitiliselt, ükskõik kui inimesesarnased või intelligentsed need meile ei tunduks.
Täpsem teave:
Heidi Kukk
meediasuhete juht
statistika levi osakond
statistikaamet
tel 625 9181
press [at] stat.ee (press[at]stat[dot]ee)
* Küsitlusuuring „The Global State of Responsible AI“, kus küsitleti üle 1000 organisatsiooni üle maailma. Konkreetne tulemus on esitatud „The AI Index Annual Report 2024“ lk. 190.
Nestor Maslej, Loredana Fattorini, Raymond Perrault, Vanessa Parli, Anka Reuel, Erik Brynjolfsson, John Etchemendy, Katrina Ligett, Terah Lyons, James Manyika, Juan Carlos Niebles, Yoav Shoham, Russell Wald, and Jack Clark, “The AI Index 2024 Annual Report,” AI Index Steering Committee, Institute for Human-Centered AI, Stanford University, Stanford, CA, April 2024.